
خط أنابيب جمع بيانات الذكاء الاصطناعي الشامل في وسوم
في الذكاء الاصطناعي, تُعتبر البيانات وقودًا. ولكن ليس كل الوقود متساويًا - فالبيانات الضعيفة قد تُسبب تحيزًا أو أخطاءً أو حتى تعطلًا للنظام. في وسوم, نتعامل مع البيانات كأصل استراتيجي. لا يقتصر مسار بيانات الذكاء الاصطناعي لدينا على جمع المعلومات الخام فحسب؛ بل يشمل أيضًا صياغة مواد تدريبية غنية وموثوقة وسهلة الاستخدام, مُصممة خصيصًا لمجالك.
1. إيجاد العملاء المناسبين
نبدأ بمشاركة عميقة في هذا المجال. سواء كنت شركة تقنية قانونية تحتاج إلى تعليقات توضيحية للقضايا, أو شركة ناشئة في مجال الرعاية الصحية تُطوّر مساعد تشخيص, فإننا نعمل على فهم فجوات البيانات لديك. يتيح لنا هذا النهج الذي يُركز على العميل تحديد معايير المصادر والتعليقات التوضيحية والامتثال لكل قطاع.
2. تحديد مصادر البيانات
من أنظمة إدارة علاقات العملاء الداخلية ونصوص الدعم إلى محتوى الويب المُستخلص, ومجموعات البيانات العامة, أو المُدخلات المُستقاة من الجمهور - مصادرنا أخلاقية ومتنوعة. نتحقق من مصادر البيانات بحثًا عن أي تحيز أو انحراف أو تغطية.
- مستندات ممسوحة ضوئيًا (ملفات PDF, عقود قانونية)
- المكالمات والملاحظات الصوتية المُنسوخة
- ملفات CSV مُهيكلة ونسخ قواعد البيانات القديمة
- بيانات الويب (الأخبار, وسائل التواصل الاجتماعي, المنتديات)
3. تحليل ما قبل التنظيف
قبل استيعاب بايت واحد, نقوم بتحليل تعقيد البيانات, والمخططات المتوقعة, وتنوع اللغات. تساعدنا هذه الخطوة على أتمتة استخراج المخططات, وتطبيع الترميز, وجاهزية معالجة اللغة الطبيعية.
import chardet
with open('contract.pdf', 'rb') as f:
raw = f.read()
print(chardet.detect(raw)) # Ensures encoding is UTF-84. محرك التجميع
نصمم مجمعات بيانات معيارية وقابلة للتطوير: برامج زحف, وأنابيب التعرف الضوئي على الحروف, ومحللات نماذج, أو تحويل الصوت إلى نص. يسجل كل مُجمِّع الأخطاء, ويتتبع الإصدارات, ويُصدِّر البيانات الخام للتنظيف.
“أداة الكشط السيئة تُولِّد ميغا بايت من الضوضاء. أما الأداة الجيدة فتمنحك معلومات ذهبية ذات صلة.”
5. التنظيف والتطبيع.
نُزيل التكرارات, ونُصحِّح الترميز, ونُقسِّم الجمل المشوهة, ونُوحِّد الوسوم, ونُحوِّل التنسيقات غير المُتسقة. وهنا يُصبح النص الخام مادة ذكاء اصطناعي قابلة للتعلم.
from bs4 import BeautifulSoup
clean_html = BeautifulSoup(raw_html, 'html.parser').get_text()
standardized = clean_html.replace('Jan', 'January')6. التحقق والتعليق التوضيحي.
تتحقق فرق ضمان الجودة لدينا من صحة كل شريحة بيانات. نستخدم مربعات التحديد, وقواعد الكيانات المُسمَّاة, والتصنيفات المُخصَّصة. الشرح متعدد الطبقات: المرحلة الأولى مُتحقق منها جماعيًا, والمرحلة الثانية مُراجعة من قِبل خبراء.
7. اختبار الذكاء الاصطناعي وقياس أدائه.
لا ننتظر حتى النشر لمعرفة مدى فعالية البيانات. نُجري تجارب صغيرة على نموذجك المُستهدف أو إطار عمل LLM, ونُحدد الميزات منخفضة التأثير أو انحرافات البيانات قبل التسليم.
8. المعالجة اللاحقة والبرامج النصية
بعد الشرح, نُضمّن البيانات الوصفية, ونُجمّع النصوص, ونُميّز الصوت, ونضغط التنسيقات بناءً على احتياجات المصب (مثل JSON أو COCO أو CSV المتوافقة مع HF).
{
"text": "Patient is experiencing chest tightness.",
"label": ["symptom"],
"language": "en",
"split": "train"
}9. التسليم النهائي والتقارير
ستتلقى تسليمًا مشفرًا مع تقرير كامل: سلسلة البيانات, ومقاييس التحقق, وأمثلة على المخرجات, وأي حالات هامشية ملحوظة.
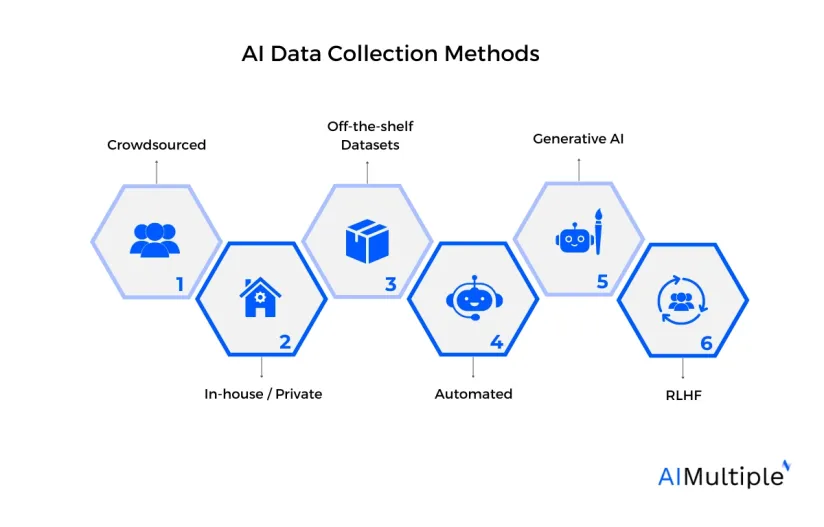 مصدر الصورة: AIMultiple
مصدر الصورة: AIMultiple“البيانات النظيفة ليست مجرد مُدخلات, بل هي مخرجات علامتك التجارية, وأخلاقياتها, وتجربة المنتج.”